

Di John Everett
Solo 70 anni fa, quando i primi computer elettronici funzionavano su tubi a vuoto e riempivano intere stanze, i ricercatori stavano già cercando di consentire a queste macchine di pensare come fanno le persone. Solo pochi anni dopo il suo inizio nel 1958, DARPA iniziò a svolgere un ruolo centrale nel realizzare questa ambizione ponendo alcune delle basi per il campo dell'intelligenza artificiale (AI). Oggi, le notevoli capacità di riconoscimento dei modelli delle reti neurali profonde, i cui circuiti e funzionamento sono modellati su quelli del cervello, hanno il potenziale per consentire applicazioni che vanno dalle macchine agricole che individuano e zapano le erbacce ad app che, con l'aiuto di la realtà viene visualizzata sugli smartphone, consente alle persone di diagnosticare e risolvere i problemi con gli elettrodomestici.
Darpa semina finanziamenti per i programmi di intelligenza artificiale in grado di spiegare chiaramente le basi delle loro azioni e come arrivano a decisioni particolari. L'intelligenza artificiale che può spiegarsi da sola dovrebbe consentire la totale fiducia degli utenti, una buona cosa poiché i sistemi basati sull'intelligenza artificiale sempre più complessi diventano all'ordine del giorno. Una prossima sfida per i ricercatori dell'IA sarà quella di emulare il buon senso umano, che è un prodotto di milioni di anni di evoluzione umana.
DARPA è stata in prima linea nello stabilire le basi dell'IA dal 1963. J.C.R. Licklider, un manager del programma nell'Ufficio Tecniche di elaborazione delle informazioni, ha finanziato il Progetto sulla cognizione assistita dalle macchine (MAC) presso il MIT e un progetto simile a Stanford per ricercare una vasta gamma di argomenti di intelligenza artificiale, come dimostrare teoremi matematici, comprensione del linguaggio naturale, robotica e scacchi. I primi ricercatori dell'IA si sono concentrati sugli scacchi perché rappresentano una difficile sfida intellettuale per l'uomo, ma le regole sono abbastanza semplici da descrivere facilmente in un linguaggio di programmazione per computer.
Negli anni '50 e '60, i computer automatizzavano compiti noiosi e laboriosi, come la contabilità dei salari o la risoluzione di complesse equazioni matematiche, come la stampa delle traiettorie delle missioni Apollo sulla luna. Non sorprende che i ricercatori dell'IA abbiano ignorato le noiose applicazioni dei computer e abbiano invece concepito l'intelligenza artificiale come computer che risolve complesse equazioni matematiche, espresse come algoritmi. Gli algoritmi sono insiemi di semplici istruzioni che i computer eseguono in sequenza per produrre risultati, come il calcolo della traiettoria di un lander lunare, quando dovrebbe sparare i suoi razzi retrò e per quanto tempo.
 |
| J.C.R. Licklider, il primo direttore dell'Ufficio Tecniche di elaborazione delle informazioni della DARPA, ha finanziato il progetto sulla cognizione assistita dalla macchina al MIT e uno sforzo analogo a Stanford per ricercare una serie di argomenti di intelligenza artificiale. |
Nonostante più di mezzo secolo di tentativi, dobbiamo ancora inventare un algoritmo che consenta ai computer di pensare come fanno le persone. All'inizio, i ricercatori dell'IA hanno scoperto che l'intelligenza non dipende solo dal pensiero, ma anche dalla conoscenza.
Considera gli scacchi. Nel mezzo del gioco, ogni giocatore deve ponderare circa 35 mosse possibili. Per ognuna di queste mosse, l'avversario del giocatore avrà circa 35 contromosse. Per determinare quale mossa fare, il giocatore deve pensare a più turni nel futuro del gioco. Per pensare in anticipo di due turni è necessario considerare 42.875 mosse. Pensare in anticipo sette mosse richiederebbe 64 miliardi di mosse. Il supercomputer IBM Deep Blue che ha battuto il campione di scacchi Gary Kasparov nel 1997 è stato in grado di valutare 200 milioni di posizioni in un secondo, quindi guardare avanti per sette turni richiederebbe poco meno di sei minuti. Tuttavia, guardare avanti in nove turni impiegherebbe quasi due giorni. Dato che le partite di scacchi in genere richiedono 50 turni, questo approccio a forza bruta di considerare tutte le possibili mosse chiaramente non funzionerà.
I campioni di scacchi usano la conoscenza del gioco per ignorare la maggior parte delle mosse potenziali che non avrebbero senso eseguire. I primi programmi di scacchi con intelligenza artificiale utilizzavano l'euristica, o regole empiriche, per decidere quali mosse prendere in considerazione. Negli anni '60, questo approccio consentì a Mac Hack VI, un programma per computer scritto da Richard Greenblatt, che stava lavorando a Project MAC presso il MIT, di vincere contro un giocatore classificato nelle partite a torneo.
Quando la centralità della conoscenza sull'intelligenza divenne evidente, i ricercatori dell'IA si concentrarono sulla costruzione di sistemi cosiddetti esperti. Questi programmi hanno acquisito le conoscenze specialistiche degli esperti in regole che potevano quindi applicare a situazioni di interesse per generare risultati utili. Se hai mai utilizzato un programma come TurboTax per preparare la dichiarazione dei redditi, hai utilizzato un sistema esperto. Edward Shortliffe creò uno dei primi sistemi esperti, MYCIN, per la sua tesi di dottorato alla Stanford University nei primi anni '70. MYCIN ha utilizzato una serie di circa 600 regole per diagnosticare le infezioni batteriche sulla base di input su sintomi e test medici. Ha raggiunto una precisione del 69 percento su una serie di casi di test, che era alla pari con gli esperti umani. La Digital Equipment Corporation ha utilizzato un sistema esperto nei primi anni '80 per configurare i suoi computer. Tali primi successi hanno portato a un boom dell'IA, con la fondazione di società come Teknowledge, Intellicorp e Inference Corporation. Tuttavia, è diventato evidente che i sistemi esperti erano difficili da aggiornare e mantenere, e avrebbero dato risposte stranamente sbagliate di fronte a input insoliti. La campagna pubblicitaria nei confronti dell'IA ha lasciato il posto alla delusione alla fine degli anni '80. Perfino il termine AI è andato in disuso ed è stato sostituito da termini come agenti distribuiti, ragionamento probabilistico e reti neurali.
La lingua è così fondamentale per la nostra esperienza quotidiana nel mondo che i primi ricercatori presumevano di poter scrivere tutte le conoscenze necessarie per abilitare un sistema di intelligenza artificiale. Dopotutto, programmiamo i computer scrivendo comandi in linguaggi di programmazione. Sicuramente, la lingua è lo strumento ideale per acquisire conoscenze. Ad esempio, un sistema esperto di ragionamento sugli animali potrebbe definire un uccello come un animale in grado di volare. Tuttavia, ci sono molte eccezioni a questa regola, come pinguini, struzzi, uccellini, uccelli morti, uccelli con una o più ali rotte e uccelli con i piedi congelati nel ghiaccio dello stagno. Eccezioni alle regole spuntano ovunque e sistemi esperti non le gestiscono con garbo.
Alla fine degli anni '80, un altro approccio all'IA stava guadagnando slancio.
Piuttosto che concentrarsi sulla scrittura esplicita della conoscenza, perché non provare a creare macchine che imparano come fanno le persone? Un robot che potrebbe imparare dalle persone, dalle osservazioni e dall'esperienza dovrebbe essere in grado di muoversi nel mondo, fermandosi a chiedere indicazioni o chiedere aiuto quando necessario.
I cosiddetti approcci di apprendimento automatico cercano di estrarre conoscenze utili direttamente dai dati sul mondo. Anziché strutturare queste conoscenze come regole, i sistemi di apprendimento automatico applicano metodi statistici e probabilistici per creare generalizzazioni da molti punti dati. I sistemi risultanti non sono sempre corretti, ma, di nuovo, non lo sono nemmeno le persone. Avere ragione il più delle volte è sufficiente per molti compiti del mondo reale.
 |
| L'intelligenza artificiale si è sviluppata in due grandi ondate. La prima ondata si è concentrata sulla conoscenza artigianale, in cui gli esperti hanno caratterizzato la loro comprensione di un particolare settore, come la preparazione della dichiarazione dei redditi, come un insieme di regole. La seconda ondata si è concentrata sull'apprendimento automatico, che crea sistemi di riconoscimento dei modelli attraverso la formazione su grandi serie di dati. I sistemi risultanti sono sorprendentemente bravi a riconoscere oggetti, come i volti. DARPA ritiene che la prossima grande ondata di progressi combinerà le tecniche della prima e della seconda ondata per creare sistemi in grado di spiegare i loro risultati e applicare il ragionamento di buon senso per agire come partner per la risoluzione dei problemi. |
Le reti neurali sono un metodo di apprendimento automatico efficace. Emulano il comportamento del cervello. Il cervello umano è costituito da una rete di cellule interconnesse chiamate neuroni. I segnali elettrici fluiscono attraverso questa rete dagli organi di senso al cervello e dal cervello ai muscoli. Il cervello umano ha qualcosa come 100 miliardi di neuroni, ognuno dei quali si collega, in media, a 7000 altri neuroni, creando trilioni di connessioni. I segnali che viaggiano attraverso questa rete arrivano ai neuroni e li stimolano (o inibiscono). Quando la stimolazione totale supera la soglia del neurone, le cellule iniziano a sparare, un'azione che propaga il segnale ad altri neuroni.
I ricercatori hanno sviluppato reti neurali artificiali che imitano questi aspetti del cervello al fine di riconoscere i modelli. Invece di scrivere un codice per programmare queste reti, i ricercatori le addestrano. Un metodo comune è chiamato apprendimento supervisionato, in cui i ricercatori raccolgono una vasta serie di dati, come le foto di oggetti da riconoscere, e li etichettano in modo appropriato. Ad esempio, per formare una rete per riconoscere gli animali domestici, i ricercatori dovrebbero raccogliere ed etichettare foto di animali come cani, gatti e conigli.
La rete è composta da strati di nodi disposti in colonne e collegati da sinistra a destra tramite collegamenti. Sul lato sinistro, ciascun nodo di input (pensa a ciascun nodo come un neurone) è assegnato a una parte particolare della foto da riconoscere. Ciascuno dei collegamenti della rete ha un peso, che determina la forza con cui propaga un segnale. Inizialmente questi pesi, che vanno da 0 a 1, sono impostati su valori casuali. L'algoritmo di allenamento mostra alla rete una foto etichettata. La luminosità di ogni parte della foto assegnata a ciascun nodo elettronico determina l'intensità di attivazione di quel nodo. I segnali dai nodi di input fanno sì che alcuni dei nodi nel layer abbiano il diritto di attivarsi, e alla fine questi segnali si propagano attraverso la rete e provocano l'attivazione di alcuni nodi nel layer di output. Nell'esempio dell'animale domestico, a ciascun nodo di output viene assegnato un tipo particolare di animale, quindi ci sarà un nodo di output per i cani, uno per i gatti e uno per i conigli. Il nodo di output che si attiva più fortemente produce la risposta della rete. L'algoritmo di allenamento confronta quella risposta con l'etichetta della foto. Se la risposta è errata, l'algoritmo si sposta all'indietro attraverso la rete, apportando piccole modifiche ai pesi di ciascun collegamento fino a quando la risposta è corretta. Questo processo si chiama backpropagation.
L'algoritmo di addestramento ripete questo processo con ciascuna foto etichettata nel set di addestramento, apportando piccole modifiche ai pesi dei collegamenti fino a quando la rete non riconosce correttamente l'animale in ogni foto. Se tutto ciò che la rete potesse fare, non sarebbe molto utile. Tuttavia, si scopre che la rete addestrata riconoscerà correttamente le innumerevoli foto di cani, gatti e conigli che non ha mai visto prima.
Estraendo la conoscenza direttamente dai dati, le reti neurali evitano la necessità di scrivere regole che descrivono il mondo. Questo approccio li rende migliori per acquisire conoscenze difficili da descrivere a parole. Ad esempio, supponiamo che sia necessario raccogliere una vasta serie di immagini di rifugiati. Scrivere una serie di regole per un sistema esperto per farlo sarebbe molto difficile. Quali sono le caratteristiche rilevanti di tali immagini? Molte, ma non tutte, le immagini dei rifugiati contengono folle di persone, ma anche le immagini di eventi sportivi, aree urbane e locali notturni. Eppure noi umani non abbiamo problemi a distinguere i rifugiati dagli appassionati di calcio. Molte delle nostre conoscenze sono difficili da esprimere a parole.
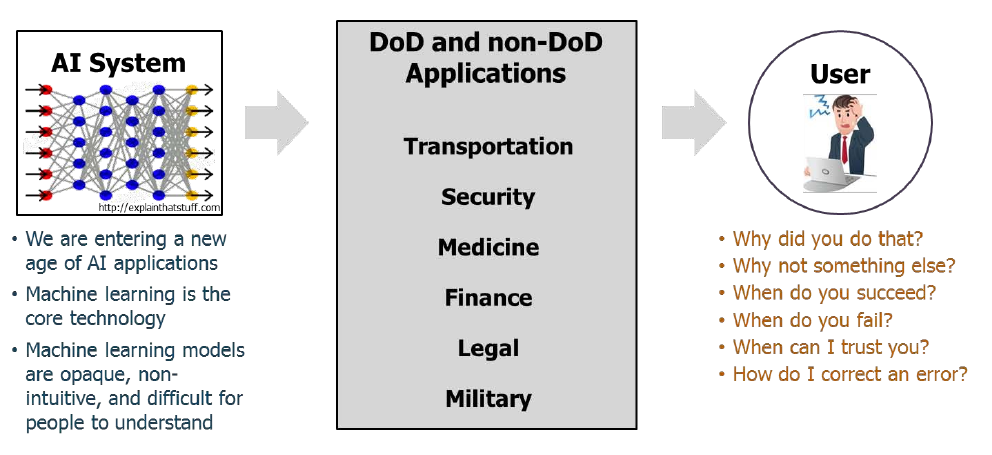 |
| Man mano che le applicazioni AI diventano più comuni, le attuali limitazioni della tecnologia diventano più evidenti. In particolare, i sistemi di apprendimento automatico non possono spiegare i loro risultati. Per affrontare questi problemi, DARPA sta eseguendo un programma chiamato AI spiegabili per sviluppare sistemi in grado di produrre spiegazioni accurate al giusto livello per un utente. I sistemi in grado di spiegare se stessi consentiranno partenariati uomo / macchina più efficaci. |
I computer sono diventati abbastanza potenti da gestire reti neurali negli anni '80, ma le reti non potevano essere molto grandi e la formazione era quasi tanto quanto la scrittura delle regole, poiché gli umani devono etichettare ogni elemento del set di formazione. Nel 1985, DARPA ha finanziato due squadre nell'ambito del programma Autonomous Land Vehicle per sviluppare auto a guida autonoma. Entrambe le squadre hanno utilizzato reti neurali per consentire ai loro veicoli di riconoscere i bordi della strada. Tuttavia, i sistemi erano facilmente confusi da foglie o tracce di pneumatici fangosi sulla strada, perché l'hardware disponibile al momento non era abbastanza potente.
Tuttavia, il programma ha stabilito le basi scientifiche e ingegneristiche dei veicoli autonomi, e alcuni ricercatori hanno continuato alla NASA per sviluppare i rover su Marte Sojourner, Spirit e Opportunity. Tutti questi veicoli autonomi hanno funzionato molto più a lungo di quanto specificato nei loro piani di missione.
Nel 2004, DARPA ha lanciato una Grand Challenge, con un premio di 1 milione di dollari assegnato al primo veicolo autonomo a tagliare il traguardo di un percorso offroad di 142 miglia nel deserto della California vicino a Barstow. Il veicolo più capace ha viaggiato a meno di 8 miglia prima di rimanere bloccato. Nel 2005, DARPA ha ripetuto la sfida su un percorso leggermente più breve ma più difficile, e questa volta cinque veicoli hanno tagliato il traguardo. I team che hanno sviluppato quei veicoli hanno utilizzato reti neurali per consentire un migliore rilevamento della pista e distinguere ostacoli come i massi dalle ombre. Molti di questi ricercatori hanno continuato a sviluppare tecnologie di auto a guida autonoma per Google, Uber e altre case automobilistiche.
Ora l'IA sembra essere ovunque. Negli ultimi anni, l'IA è stata costantemente nelle notizie, a causa dei rapidi progressi nel riconoscimento del volto, nella comprensione del parlato e nelle auto a guida autonoma. Stranamente, questa ondata di rapidi progressi è avvenuta in gran parte perché gli adolescenti erano ansiosi di giocare a videogiochi altamente realistici. Il video consiste in una serie di immagini fisse trasmesse sullo schermo, una dopo l'altra, per creare l'illusione del movimento. I video realistici richiedono la creazione e la visualizzazione di molte immagini ad alta definizione, perché devono essere visualizzate a una velocità feroce di almeno 60 immagini al secondo. Gli schermi video sono costituiti da una fitta serie rettangolare di piccoli punti, chiamati pixel. Ogni pixel può illuminarsi in uno degli oltre 16 milioni di colori. I processori alla base dei videogiochi ad azione rapida devono creare un flusso costante di immagini basato sulle azioni del giocatore e trasferirle sullo schermo in rapida successione.
Immettere l'unità di elaborazione grafica o GPU, un chip di computer appositamente progettato per questa attività. Le GPU elaborano rapidamente grandi matrici di numeri che rappresentano i colori dei pixel che compongono ciascuna immagine.
Nel 2009, NVIDIA ha rilasciato nuove potenti GPU e presto i ricercatori hanno scoperto che questi chip sono ideali per l'addestramento delle reti neurali. Ciò ha consentito l'addestramento di reti neurali profonde costituite da dozzine di strati di neuroni. I ricercatori hanno applicato algoritmi inventati negli anni '80 e '90 per creare potenti riconoscitori di schemi. Hanno scoperto che i livelli iniziali di una rete profonda potevano riconoscere piccole caratteristiche, come i bordi, consentendo ai livelli successivi di riconoscere caratteristiche più grandi come occhi, nasi, coprimozzi o parafanghi. Fornire più dati di formazione rende tutte le reti neurali migliori, fino a un certo punto. Le reti neurali profonde possono utilizzare più dati per migliorare la precisione del riconoscimento ben oltre il punto in cui altri approcci cessano di migliorare. Questa prestazione superiore ha reso le reti profonde il pilastro dell'attuale ondata di applicazioni AI.
Insieme a GPU e algoritmi intelligenti, Internet ha consentito la raccolta e l'etichettatura delle enormi quantità di dati necessari per addestrare reti neurali profonde. Prima che fosse possibile il riconoscimento automatico dei volti, Facebook forniva agli utenti gli strumenti per etichettare le loro foto. I siti Web di crowdsourcing reclutano manodopera a basso costo che le aziende di intelligenza artificiale possono toccare per etichettare le immagini. La conseguente abbondanza di dati di allenamento fa sembrare che i sistemi di intelligenza artificiale con capacità sovrumane stiano per conquistare il mondo.
 |
| Una volta addestrati, gli attuali sistemi di apprendimento automatico non si adattano più ai loro ambienti. Il programma DARPA Lifelong Learning Machines sta studiando modi per consentire ai sistemi di imparare dalle sorprese e adattarsi ai cambiamenti nei loro ambienti. Il programma Autonomia assicurata sta sviluppando approcci per produrre garanzie matematiche che tali sistemi funzioneranno in modo sicuro e prevedibile in una vasta gamma di condizioni operative. |
Tuttavia, le reti neurali profonde sono apprendenti terribilmente inefficienti, che richiedono milioni di immagini per imparare a rilevare gli oggetti. Sono meglio pensati come riconoscitori di schemi statistici prodotti da un algoritmo che mappa i contorni dei dati di allenamento. Dai a questi algoritmi abbastanza immagini di cani e gatti e troveranno le differenze che distinguono l'una dall'altra, che potrebbe essere la trama della pelliccia, la forma dell'orecchio o qualche caratteristica che trasmette un senso generale di "dogness" o "catness".
Per alcune applicazioni, questa inefficienza non è un problema. I motori di ricerca su Internet possono ora trovare immagini di qualsiasi cosa, dai gatti seduti sulle valigie alle persone che giocano a frisbee su una spiaggia. Per le applicazioni in cui i dati di addestramento sono scarsi, le reti neurali possono generarli.
Per alcune applicazioni, questa inefficienza non è un problema. I motori di ricerca su Internet possono ora trovare immagini di qualsiasi cosa, dai gatti seduti sulle valigie alle persone che giocano a frisbee su una spiaggia. Per le applicazioni in cui i dati di addestramento sono scarsi, le reti neurali possono generarli.
Un approccio chiamato reti contraddittorie generative prende un set di addestramento di immagini e mette due reti una contro l'altra. Uno tenta di generare nuove immagini simili al set di addestramento e l'altro tenta di rilevare le immagini generate. Su più round, le due reti migliorano in termini di generazione e rilevamento, fino a quando le immagini prodotte non sono nuove, ma utilmente vicine a quelle reali, in modo che possano essere utilizzate per aumentare un set di allenamento. Si noti che non sono necessarie etichette per questa fase di generazione, poiché l'obiettivo è generare nuove immagini, non classificare quelle esistenti.
Tuttavia, ci manca ancora una solida base teorica per spiegare come funzionano le reti neurali. Di recente, i ricercatori hanno scoperto che apportare una minuscola modifica a un'immagine provoca un'errata classificazione errata. L'immagine di un panda viene improvvisamente identificata come una scimmia, anche se sembra ancora un panda. Comprendere queste anomalie è essenziale, poiché i sistemi di intelligenza artificiale vengono sempre più utilizzati per prendere decisioni critiche in aree diverse come la diagnosi medica e i veicoli a guida autonoma.
Un altro approccio all'apprendimento automatico si basa su segnali provenienti dall'ambiente per rafforzare il buon comportamento e sopprimerlo. Ad esempio, il programma AlphaGo Zero può insegnare a se stesso a giocare al gioco da tavolo Vai a livello di campionato senza alcun input umano, oltre alle regole del gioco. Inizia giocando contro se stesso, facendo mosse casuali. Usa le regole del gioco per segnare i suoi risultati e questi punteggi rafforzano le tattiche vincenti. Questo cosiddetto apprendimento di rinforzo può essere altamente efficace in situazioni in cui ci sono chiare ricompense per un comportamento efficace. Tuttavia, determinare quale comportamento ha creato il risultato desiderato in molte situazioni del mondo reale può essere difficile.
Mentre l'IA si fa sempre più strada in contesti industriali e prodotti di consumo, le aziende stanno scoprendo che i suoi sostanziali benefici derivano da costi, sotto forma di complessità ingegneristica e requisiti unici per la manutenzione continua. L'intensità computazionale dei sistemi di intelligenza artificiale richiede rack di server e dispositivi di rete, che devono essere protetti e costantemente monitorati per le intrusioni informatiche. L'appetito insaziabile di questi sistemi per i dati spesso li rende dipendenti da molti database aziendali diversi, il che richiede un coordinamento sempre crescente delle operazioni all'interno dell'organizzazione. E infine, i sistemi di apprendimento automatico devono essere continuamente riqualificati per mantenerli in sintonia con il mondo mentre cambia e si evolve continuamente. Questa riqualificazione richiede un team di esperti data scientist e ingegneri di intelligenza artificiale, che tendono a scarseggiare.
In definitiva, le persone sono ancora studenti molto più efficaci delle macchine.
Possiamo imparare da insegnanti, libri, osservazioni ed esperienze. Possiamo applicare rapidamente ciò che abbiamo appreso a nuove situazioni e impariamo costantemente nella vita quotidiana. Possiamo anche spiegare le nostre azioni, che possono essere molto utili durante il processo di apprendimento. Al contrario, i sistemi di apprendimento profondo fanno tutto il loro apprendimento in una fase di addestramento, che deve essere completa prima di poter riconoscere in modo affidabile le cose nel mondo. Cercare di imparare mentre si fa può creare un disastro catastrofico, poiché la backpropagation apporta modifiche all'ingrosso ai pesi dei collegamenti tra i nodi della rete neurale. Il programma DARPA Lifelong Learning Machines sta esplorando i modi per consentire alle macchine di apprendere mentre si fa senza dimenticare catastroficamente. Tale capacità consentirebbe ai sistemi di migliorare al volo, recuperare dalle sorprese e impedire loro di spostarsi fuori sincrono con il mondo.
Possiamo imparare da insegnanti, libri, osservazioni ed esperienze. Possiamo applicare rapidamente ciò che abbiamo appreso a nuove situazioni e impariamo costantemente nella vita quotidiana. Possiamo anche spiegare le nostre azioni, che possono essere molto utili durante il processo di apprendimento. Al contrario, i sistemi di apprendimento profondo fanno tutto il loro apprendimento in una fase di addestramento, che deve essere completa prima di poter riconoscere in modo affidabile le cose nel mondo. Cercare di imparare mentre si fa può creare un disastro catastrofico, poiché la backpropagation apporta modifiche all'ingrosso ai pesi dei collegamenti tra i nodi della rete neurale. Il programma DARPA Lifelong Learning Machines sta esplorando i modi per consentire alle macchine di apprendere mentre si fa senza dimenticare catastroficamente. Tale capacità consentirebbe ai sistemi di migliorare al volo, recuperare dalle sorprese e impedire loro di spostarsi fuori sincrono con il mondo.
La conoscenza di una rete neurale addestrata è contenuta nelle migliaia di pesi sui suoi collegamenti. Questa codifica impedisce alle reti neurali di spiegare i loro risultati in modo significativo. DARPA sta attualmente eseguendo un programma chiamato Explainable AI per sviluppare nuove architetture di apprendimento automatico in grado di produrre spiegazioni accurate delle loro decisioni in una forma che abbia senso per gli umani. Man mano che gli algoritmi di intelligenza artificiale diventano più ampiamente utilizzati, una ragionevole auto-spiegazione aiuterà gli utenti a capire come funzionano questi sistemi e quanto fidarsi di loro in varie situazioni.
La vera svolta per l'intelligenza artificiale arriverà quando i ricercatori troveranno un modo per imparare o acquisire in altro modo il buon senso. Senza buon senso, i sistemi di intelligenza artificiale saranno strumenti potenti ma limitati che richiedono input umani per funzionare. Con buon senso, un'intelligenza artificiale potrebbe diventare un partner nella risoluzione dei problemi. Gli attuali sistemi di intelligenza artificiale oggi sembrano sovrumani perché possono fare ragionamenti complessi rapidamente in specialità ristrette. Questo crea l'illusione di essere più intelligenti e più capaci di quanto realmente siano. Ad esempio, è possibile utilizzare un motore di ricerca su Internet per trovare immagini di gatti seduti su valigie.
Tuttavia, nessuna IA corrente può utilizzare l'immagine per determinare se il gatto si adatta alla valigia. Per l'IA, la cosa che riconosciamo come un animale peloso che fa le fusa, usa una lettiera e rovina il singolo mobile più costoso della casa con i suoi artigli aguzzi è solo una sfocata trama bidimensionale. L'intelligenza artificiale non ha concepimento di un gatto tridimensionale.
Cosa succederebbe se qualcuno mettesse un gatto in una valigia? La sofferenza come possibilità viene in mente, perché impariamo da grandi a considerare le probabili conseguenze delle nostre azioni. Sappiamo anche che un gatto peluche può entrare in una valigia ermetica senza alcun effetto negativo, perché classifichiamo le cose in base alle loro proprietà, come essere vivi, non solo dal loro aspetto (in questo caso, un giocattolo inanimato che sembra proprio un vero gatto). Nessun sistema di intelligenza artificiale oggi può fare questo tipo di ragionamento, che si basa sull'immensa quantità di conoscenza di buon senso che accumuliamo nel corso della nostra vita.
La conoscenza del senso comune è così pervasiva nella nostra vita che può essere difficile da riconoscere. Ad esempio, la maggior parte delle persone potrebbe facilmente ordinare le foto dei mobili per trovare divani neri con le gambe bianche. Come esperimento, prova a trovare tali immagini su Internet. Nel 2018, almeno, i risultati della tua ricerca conterranno principalmente immagini di divani neri e divani bianchi, con le immagini di vari altri divani inseriti nel caso. Il colore delle gambe sarà quello che è di moda, perché non capiamo ancora come creare sistemi di intelligenza artificiale in grado di capire le parti degli oggetti.
I sistemi di intelligenza artificiale con buon senso alla fine potrebbero diventare partner nella risoluzione dei problemi, piuttosto che semplici strumenti. Ad esempio, in situazioni di emergenza, le persone tendono a prendere decisioni rapide sulla causa del problema e ignorare le prove che non supportano il loro punto di vista.
La causa dell'incidente di Three Mile Island è stata una valvola aperta bloccata che ha permesso all'acqua di raffreddamento di fuoriuscire dal recipiente di contenimento del reattore.
Il calore del reattore ha portato l'acqua rimanente a diventare vapore, aumentando la pressione del serbatoio. Gli operatori hanno deciso che l'alta pressione significava che c'era troppa acqua e ha peggiorato la situazione scavalcando il sistema di raffreddamento automatico di emergenza. Un'intelligenza artificiale in grado di comprendere le conversazioni nella sala di controllo e di esaminarle contro i propri modelli di funzionamento del reattore potrebbe essere in grado di suggerire possibilità alternative prima che gli operatori umani si impegnino in una determinata linea di azione. Per agire come un prezioso partner in tali situazioni, il sistema di intelligenza artificiale avrà bisogno di un buon senso sufficiente per sapere quando parlare e cosa dire, il che richiederà che abbia una buona idea di ciò che ogni persona nella sala di controllo sa. L'interruzione per dichiarare l'ovvio comporterebbe rapidamente la sua disattivazione, in particolare in condizioni di stress.DARPA sta organizzando un'importante iniziativa per creare la prossima generazione di tecnologie di intelligenza artificiale, basandosi sui suoi cinque decenni di creazione della tecnologia di intelligenza artificiale per definire e modellare ciò che verrà dopo. I consistenti investimenti in ricerca e sviluppo di AI in DARPA aumenteranno per finanziare gli sforzi nei seguenti settori:
Nuove funzionalità. I programmi DARPA applicano sistematicamente le tecnologie di intelligenza artificiale a diversi problemi, tra cui analisi in tempo reale di sofisticati attacchi informatici, rilevamento di immagini fraudolente, comprensione del linguaggio umano, progressi biomedici e controllo degli arti protesici. DARPA promuoverà le tecnologie di intelligenza artificiale per consentire l'automazione di processi aziendali complessi, come l'accreditamento lungo e accurato dei sistemi software necessari per l'aviazione, le infrastrutture critiche e i sistemi militari. L'automazione di questo processo di accreditamento con AI noti e altre tecnologie ora sembra possibile e consentirebbe l'implementazione di tecnologie più sicure in meno tempo.
AI robusto. Come notato sopra, le modalità di fallimento delle tecnologie AI sono poco comprese. I dati utilizzati per addestrare tali sistemi possono essere danneggiati. Il software stesso è vulnerabile agli attacchi informatici. DARPA sta lavorando per affrontare queste carenze sviluppando nuovi quadri teorici, supportati da ampie prove sperimentali, per rafforzare gli strumenti di intelligenza artificiale che sviluppiamo.
AI ad alte prestazioni. In combinazione con set di dati di grandi dimensioni e librerie software, i miglioramenti delle prestazioni del computer nell'ultimo decennio hanno consentito il successo dell'apprendimento automatico. Maggiori prestazioni a bassa potenza elettrica sono essenziali per consentire questo utilizzo dell'IA per applicazioni di data center e per implementazioni tattiche. DARPA ha dimostrato l'elaborazione analogica di algoritmi AI che funzionano mille volte più velocemente utilizzando una potenza mille volte inferiore rispetto ai processori digitali all'avanguardia.
Una nuova ricerca esaminerà i progetti hardware specifici per l'IA e affronterà l'inefficienza dell'apprendimento automatico riducendo drasticamente i requisiti per i dati di addestramento etichettati.
AI di nuova generazione. DARPA ha assunto la guida nella ricerca pionieristica per sviluppare la prossima generazione di algoritmi AI, che trasformeranno i computer da strumenti in partner per la risoluzione dei problemi. Una nuova ricerca consentirà ai sistemi di intelligenza artificiale di acquisire e ragionare con conoscenza di buon senso. La ricerca e sviluppo di DARPA ha prodotto i primi successi di intelligenza artificiale, come sistemi esperti e utility di ricerca, e più recentemente ha avanzato strumenti e hardware di apprendimento automatico. DARPA sta ora creando la prossima ondata di tecnologie AI che consentirà agli Stati Uniti di mantenere il proprio vantaggio tecnologico in questa area critica.
Articolo tratto dalla brochure della DARPA del 2018 per il sessantennale dalla sua fondazione; documento in PDF che puoi scaricare qui sotto.
Nessun commento:
Posta un commento
Nota. Solo i membri di questo blog possono postare un commento.